Enzyme sind Proteine, die dabei helfen, Moleküle aufzubauen, abzubauen oder umzubauen. In Backmischungen sorgen sie zum Beispiel für optimale Teigeigenschaften, in Waschmitteln für die Entfernung von Flecken, als Glukosesensor dienen sie der Blutzuckerbestimmung.
Sie können chemische Vorgänge beschleunigen und bei der Produktion von Lebensmitteln oder pharmazeutischen Wirkstoffen behilflich sein: Enzyme. Da sie viele chemische Prozesse unter anderem umweltfreundlicher gestalten können, macht sie das gefragter denn je, auch in der Forschung, etwa um neue Wege zur Synthese von Substanzen zu entwickeln. „Die publizierten Forschungsergebnisse können aber oft nicht nachvollzogen werden, da Angaben zu den Reaktionsbedingungen, wie etwa die Temperatur, fehlen“, erklärt Jürgen Pleiss, Professor am Institut für Biochemie und Technische Biochemie der Universität Stuttgart. Deshalb hat er mit seinem Team mit EnzymeML ein standardisiertes Datenaustauschformat entwickelt, das es ermöglicht, die Ergebnisse der Experimente mit Enzymen komplett zu erfassen und das darüber hinaus die Daten strukturiert ablegt.
„Damit sind wir Vorreiter im Bereich der Enzyme, weil für die Biokatalyse noch nichts Derartiges existierte und die Daten sehr komplex sind“, sagt Jürgen Pleiss. Weltweit gibt es viele Datenbanken über Enzyme. Derzeit sind die Inhalte spezialisierter Datenbanken aber kaum vergleichbar, da sie unterschiedliche Datenmodelle und Ausgabeformate verwenden. EnzymeML könnte als universelles, standardisiertes Austauschformat für spezialisierte Datenbanken zum Austausch enzymatischer Daten dienen.
„Man kann sich das vorstellen als einen Container, in dem alles enthalten ist, was ich brauche, um das Experiment wiederholen zu können“.
Prof. Dr. Jürgen Pleiss
In mehreren Studien wurde festgestellt, dass bis zu 70 Prozent der Ergebnisse von Experimenten in erneuten Studien nicht reproduziert werden konnten. Diese sogenannte Replikationskrise war unter anderem ausschlaggebend für die Formulierung der FAIR-Data Principles.
Aufbauend darauf wurde in Deutschland im Jahr 2020 die Initiative Nationale Forschungsdateninfrastruktur (NFDI) ins Leben gerufen, die die Nutzungsmöglichkeiten von Daten für die Wissenschaft und Gesellschaft verbessern will.
Das ML in EnzymeML steht für „Markup Language“, eine maschinenlesbare Sprache, die Regeln vorgibt, wie ein Text gegliedert und formatiert wird. So werden die Daten normiert und können sowohl von Computern als auch von Menschen gelesen werden. Die Messergebnisse und die Metadaten werden so abgespeichert, dass Experimente für jeden nachvollziehbar sind, da alle relevanten Parameter wie beispielsweise Konzentrationen von Enzym und Substrat oder Temperatur, Lösungsmittel und pH-Wert erfasst werden. „Man kann sich das vorstellen als einen Container, in dem alles enthalten ist, was ich brauche, um das Experiment wiederholen zu können“, erklärt Jürgen Pleiss.
EnzymeML unterstützt Wissenschaftlerinnen und Wissenschaftler dabei, Daten vollständig zu erfassen. Damit ist EnzymeML ein wichtiger Schritt in Richtung der „FAIR Data Principles“. Das sind Grundsätze, die Forschungsdaten erfüllen müssen, um nachhaltig nutzbar zu sein. Sie müssen auffindbar sein (findable), zugänglich (accessible), interoperabel (interoperable) und wiederverwendbar (reusable). EnzymeML erfüllt diese Grundsätze. Eine integrierte Schnittstelle ermöglicht zudem fortgeschrittene Modellierungsansätze, da die Daten von einer Modellierungssoftware ausgelesen werden können. Die Simulation von enzymkatalysierten Reaktionen vertiefen unser Verständnis der zugrundeliegenden Mechanismen und ermöglichen die Entwicklung neuartiger Reaktionswege.
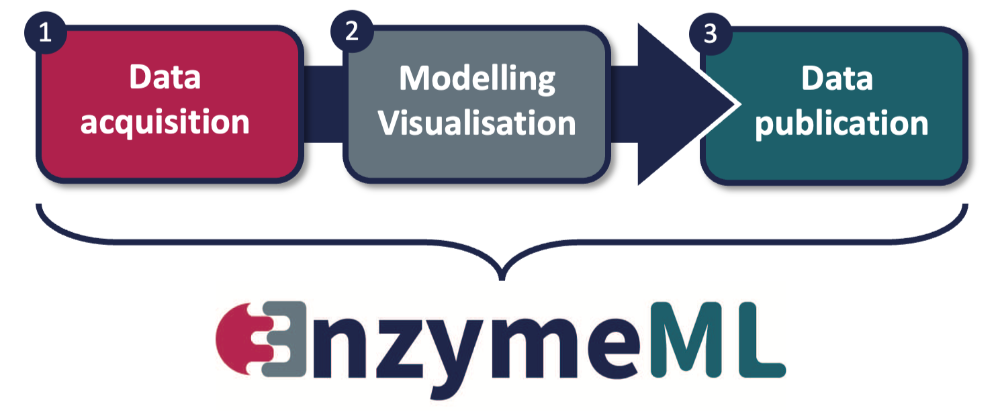
Komplettlösung für die Durchführung und Analyse biokatalytischer Experimente
EnzymeML bietet eine Komplettlösung für die Durchführung und Analyse biokatalytischer Experimente: ein standardisiertes Datenaustauschformat sowie eine Schnittstelle zu Datenbanken, elektronische Laborjournale für die Datenerfassung und zuverlässige und zugängliche Datenspeicher wie beispielsweise DaRUS, das Datenrepositorium der Universität Stuttgart, das auf der Software von Dataverse basiert. Das ermöglicht den nahtlosen Fluss enzymatischer Daten von der Messung über die Modellierung bis zur Veröffentlichung, ohne dass manuelle Eingriffe wie Umformatierung oder Bearbeitung erforderlich sind.
Das Dataverse-Projekt ist eine Open-Source-Webanwendung zum Teilen, Archivieren, Zitieren und Analysieren von Forschungsdaten. Es erleichtert die Bereitstellung von Daten und ermöglicht dadurch, dass Forschung leichter reproduziert werden kann.
Daten und Metadaten des Experiments und des Modellierungsprozesses werden in einer einzigen Datei oder in einem EnzymeML-Dataverse-Eintrag zusammengefasst, der über einen DOI abgerufen werden kann und als maschinenlesbare Mikropublikation dient. Die Gesamtheit der EnzymeML-Dokumente garantiert die Reproduzierbarkeit von enzymatischen Experimenten und ermöglicht die erneute Analyse von enzymatischen Daten. Somit trägt EnzymeML zur Vision einer einheitlichen Forschungsdateninfrastruktur für die Katalyseforschung bei. „Das Datenaustauschformat kann aber auch auf andere Bereiche übertragen werden, zum Beispiel auf die Messung von Strömung in porösen Medien“, ergänzt Jürgen Pleiss. „Große Daten, die durch experimentelle Verfahren unter kontrollierten Reaktionsbedingungen gewonnen wurden, sind außerdem ein wertvoller Trainingssatz für maschinelle Lernverfahren.“
Manuela Mild | SimTech Science Communication
Das von der DFG geförderte Konsortium NFDI4Chem entwickelt und pflegt eine Daten-Infrastruktur für den Forschungsbereich Chemie. EnzymeML ist ein Beitrag zu einer Forschungsdaten-Infrastruktur in der Enzymologie und Biokatalyse. In NFDI4Chem dient EnzymeML als Schaufenster, um die Vorteile einer guten wissenschaftlichen Praxis der Datenverwaltung zu demonstrieren. Diese Konzepte lassen sich auch auf die Beschreibung nicht-enzymatischer Reaktionen übertragen.
Zum Nachlesen
Pleiss, J. Standardized data, scalable documentation, sustainable storage – EnzymeML as a basis for FAIR data management in biocatalysis. ChemCatChem 13, 3909–3913 (2021). doi: 10.1002/cctc.202100822
Range J, Halupczok C, Lohmann J, Swainston N, Kettner C, Bergmann FT, Weidemann A, Wittig U, Schnell S, Pleiss J, 2022. EnzymeML—a data exchange format for biocatalysis and enzymology. FEBS J 289: 5864-5874. doi: 10.1111/febs.16318
Lauterbach, S., Dienhart, H., Range, J. et al. EnzymeML: seamless data flow and modeling of enzymatic data. Nat Methods 20, 400–402 (2023). doi: 10.1038/s41592-022-01763-1
Pleiss J, 2024. FAIR data and software: improving efficiency and quality of biocatalytic science. ACS Catal 14: 2709−2718. doi: 10.1021/acscatal.3c06337

Über den Wissenschaftler
Jürgen Pleiss hat Physik studiert. Er promovierte am Max-Planck-Institut für Biologie und an der Universität Tübingen, trat anschließend in die Firma Biostructure S.A. in Straßburg ein, um Software für die Proteinmodellierung zu entwickeln und wechselte dann an die Universität Stuttgart, wo er seit 1995 die Bioinformatik-Gruppe am Institut für Biochemie und Technische Biochemie leitet. Heute ist er Professor für Bioinformatik. Seine Forschungsaktivitäten konzentrieren sich auf das Design von Enzymen durch die Kombination von Bioinformatik und molekularen Simulationsmethoden sowie auf die Anwendung der computergestützten Biologie in der weißen und roten Biotechnologie. Jürgen Pleiss engagiert sich außerdem beim Aufbau einer Nationalen Forschungsdateninfrastruktur für Chemie, NFDI4Chem.